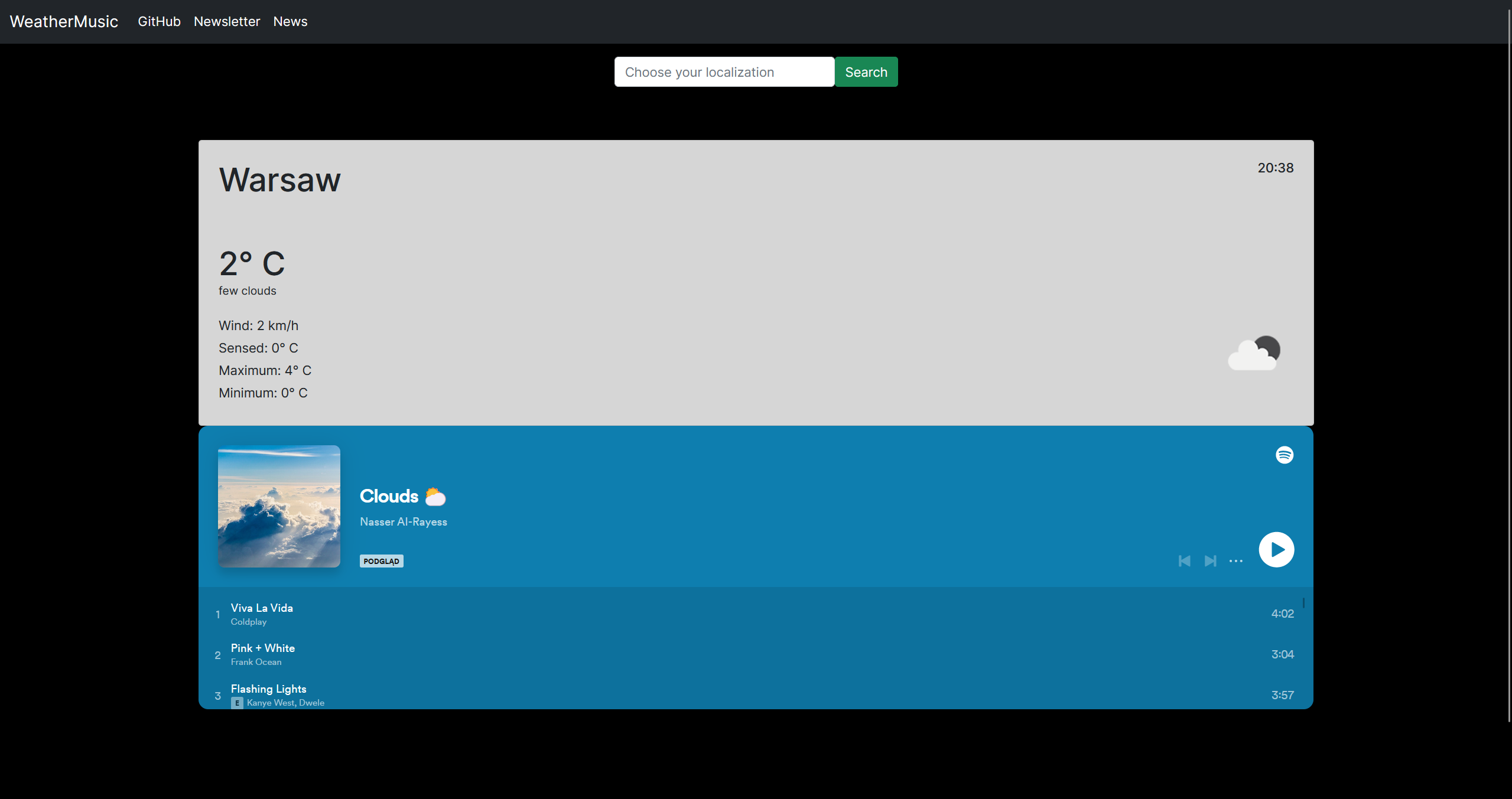
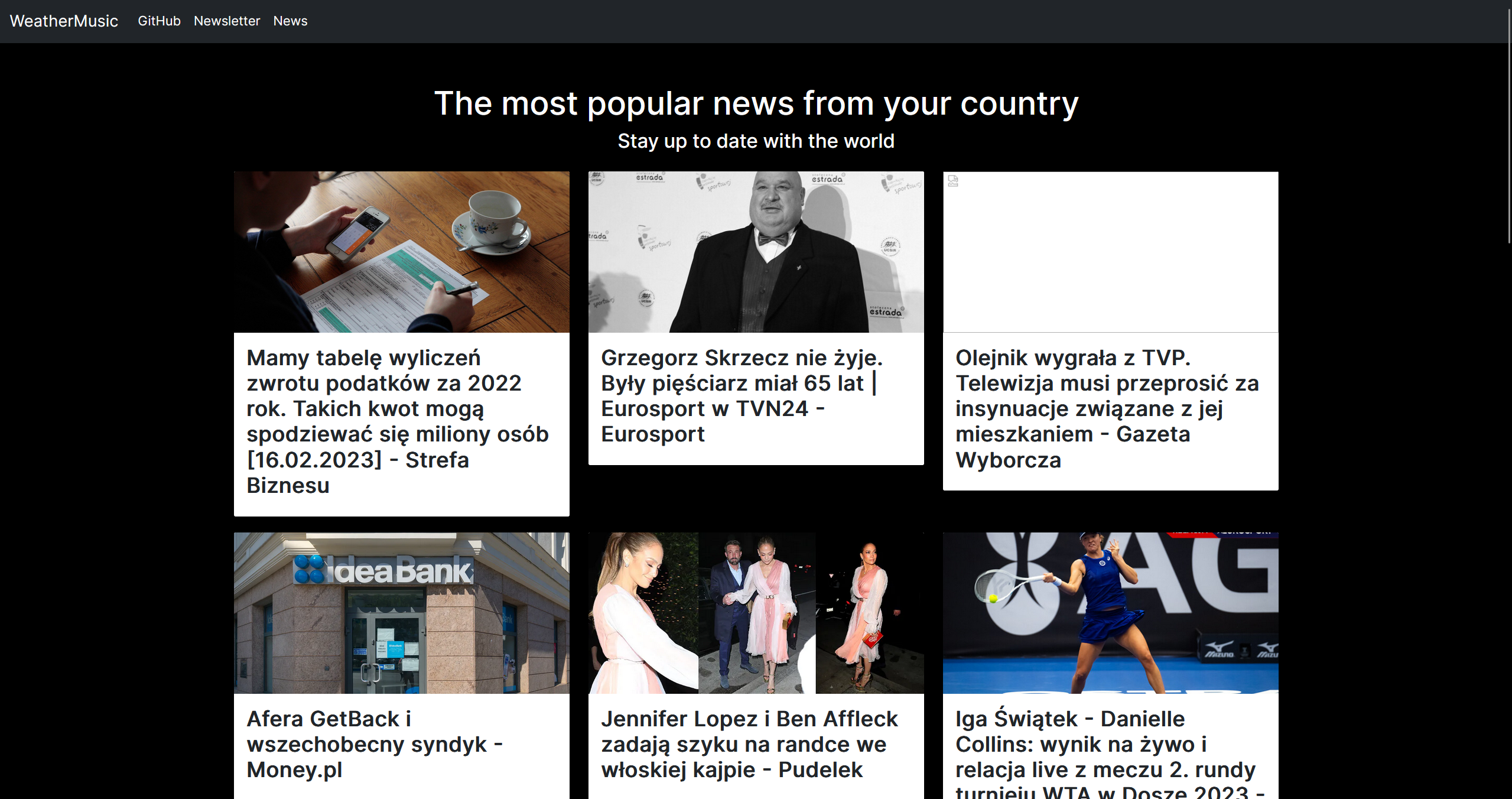
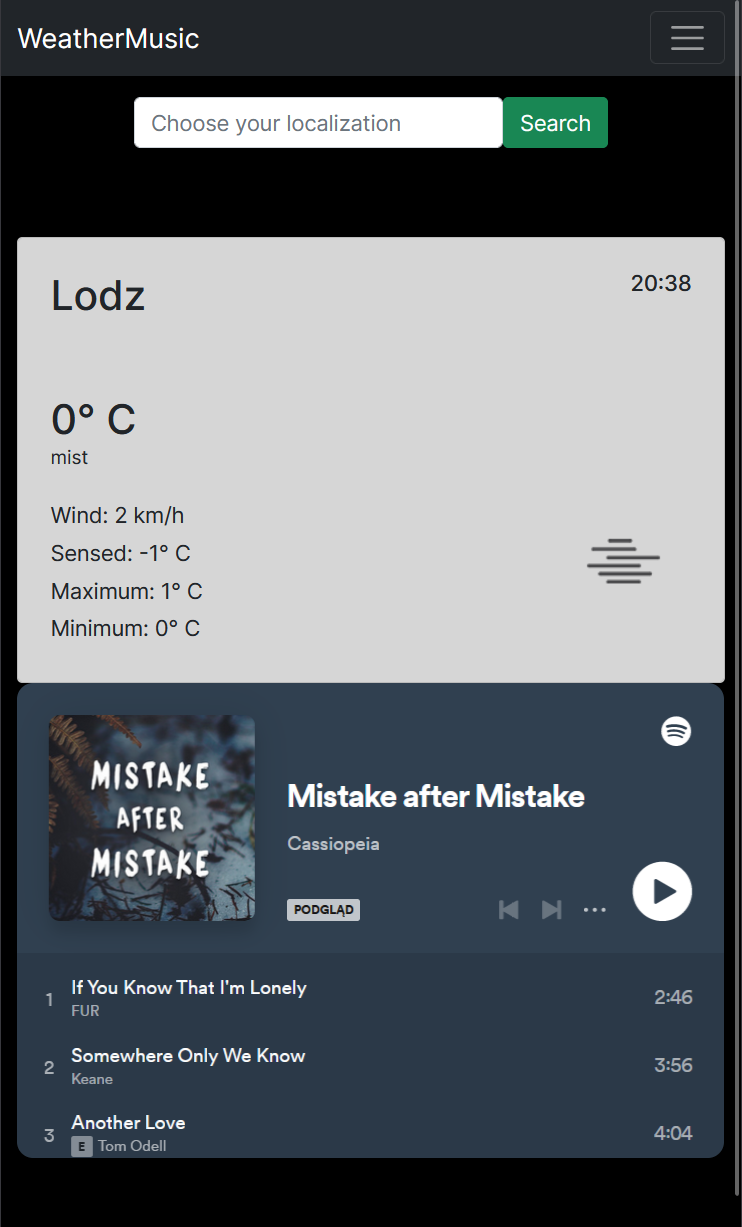
Music based on the weather and the most popular news in your country.
This application allows you to check actuall weather and give a random playlist on spotify based on weather.
You also check the most popular news in your country.
For more content you can register to the newsletter to get weakly interesting informations.
The goal of this app is to build an app that shows the current trending Github
repositories fetched from a public API. The design and business specifications have been
provided below. We expect you to follow it as closely as possible.
The application consists of three screens. The home screen where you search and display
a list of repositories. Repo Details screen where you list the necessary information about the
repository. Contributors screen where his/her details and list of repositories are mentioned.
Necessary information is listed below.
Home:
· A search bar to search from git API's
· A recycler view using card view to display the search results.
· The results are sorted in the descending order of the "watchers" count.
· The results count should be limited to 10.
· Clicking on an item to go to Repo Details Activity
· Dynamic Filters have to be implemented on the results displayed.
· Implementation/Use-case of the filter is up to your imagination.
Repo Details:
· This Activity should have a detailed description of the selected item.
· Details such as Image, Name, Project Link, Description, Contributors should be
displayed.
· When clicked on project link the URL should be opened in an In-app Browser(Web
View)
· When clicked on a contributor it should go to Contributor Details
Contributor Details:
· This Activity should have a detailed description of the contributor.
· Details such as Contributor Avatar(image),RepoList.
· Recycler view with card view should be used to display the repo list.
· Clicking on an item from the repo list it should display the detailed description of the
repo in a new Activity (Repo Details).
API Details:
The complete API docs are available: https://developer.github.com/v3/search/
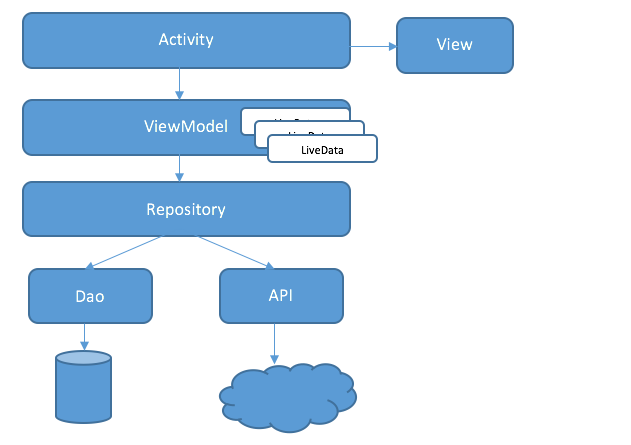
Application Architecture
The main advatage of using MVVM, there is no two way dependency between ViewModel and Model unlike MVP. Here the view can observe the datachanges in the viewmodel as we are using LiveData which is lifecycle aware. The viewmodel to view communication is achieved through observer pattern (basically observing the state changes of the data in the viewmodel).
Retrofit with OkHTTP3 (with 2 hrs offline API caching)
Stetho for debugging
Glide
Dagger2
Shimmer
Realm (For full offline support, was not part of initial requirement but implemented for demo purpose)
Google gson
License
Copyright (C) 2019-2020 JINESH SONI
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
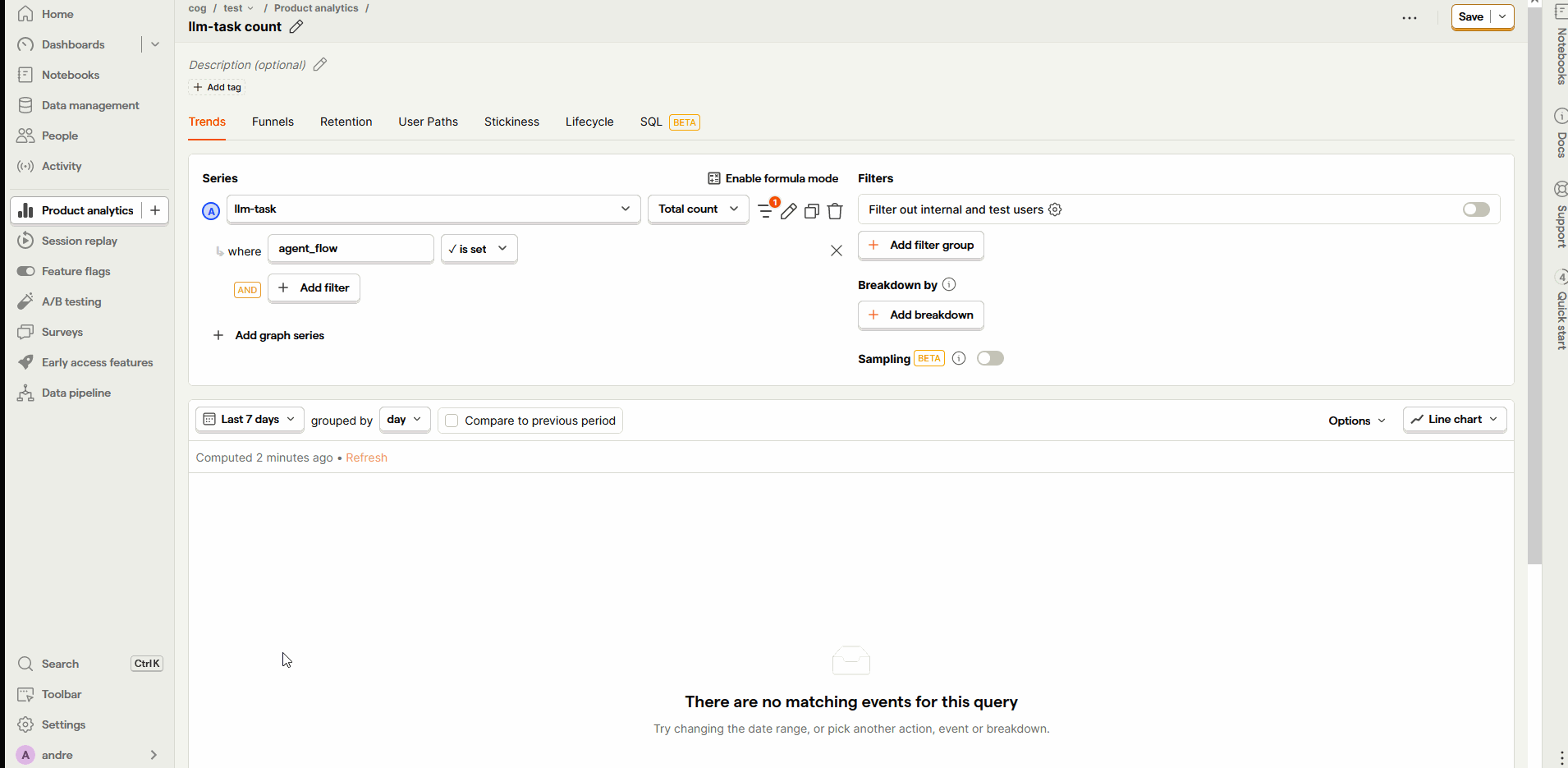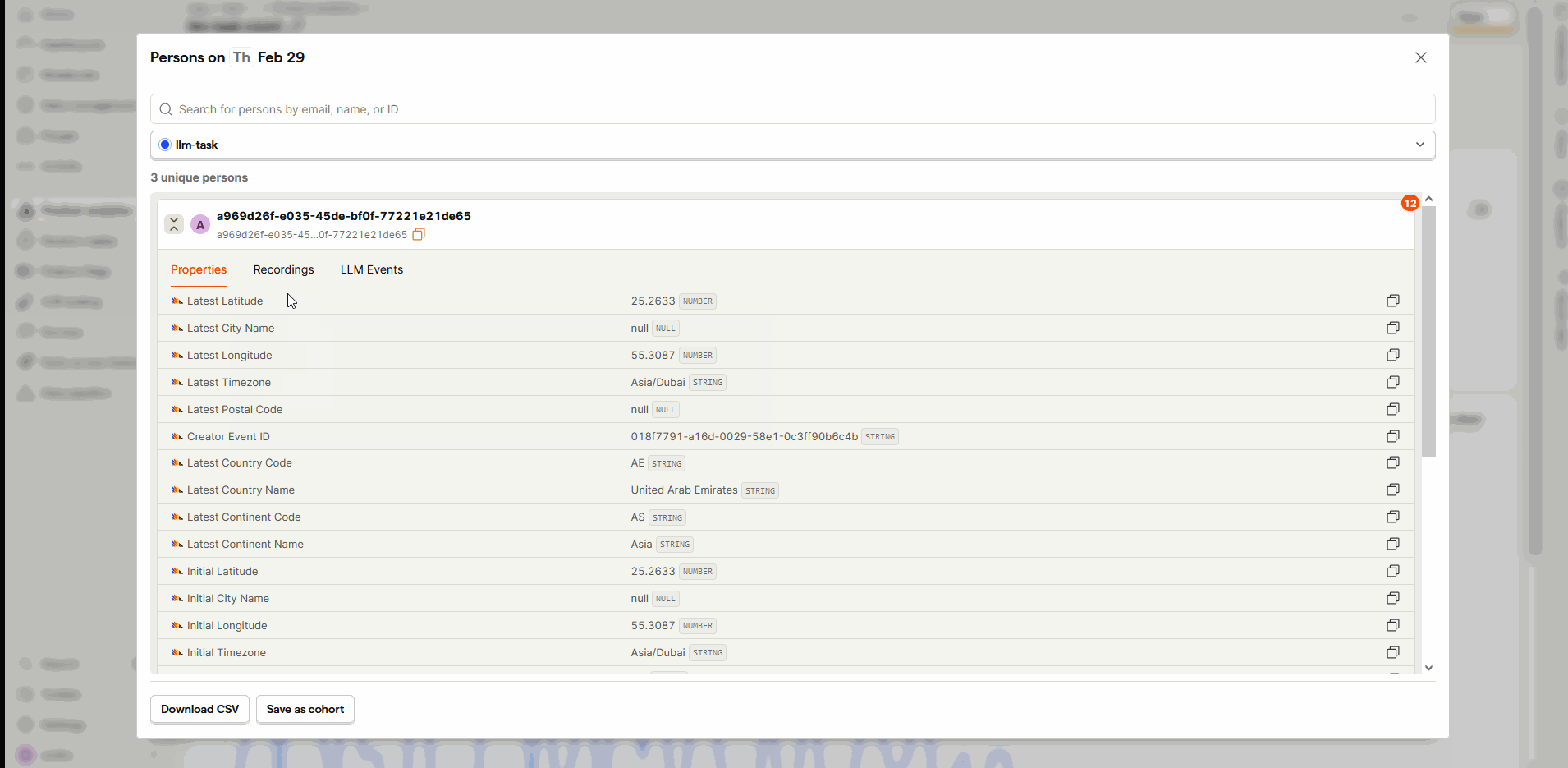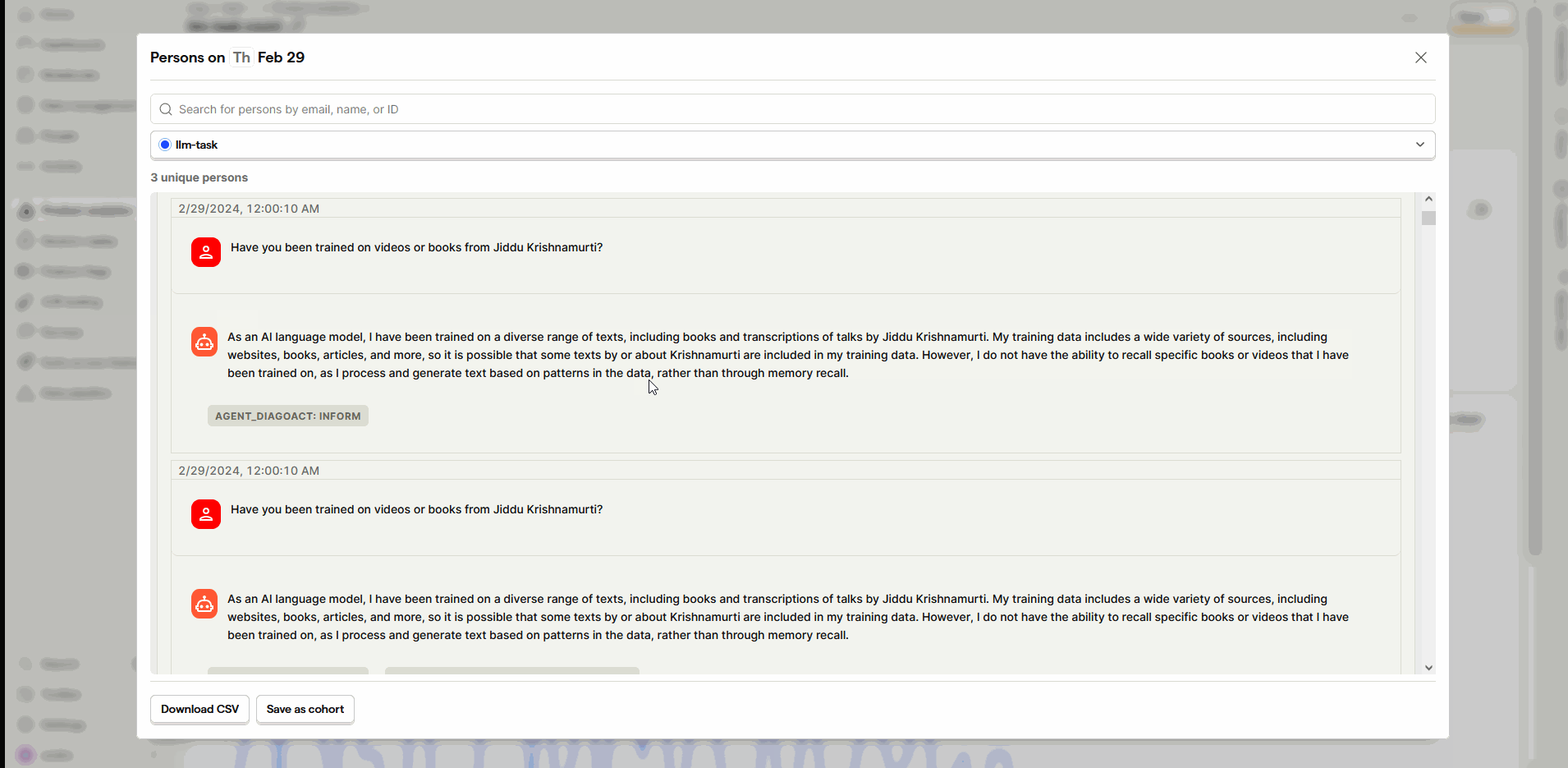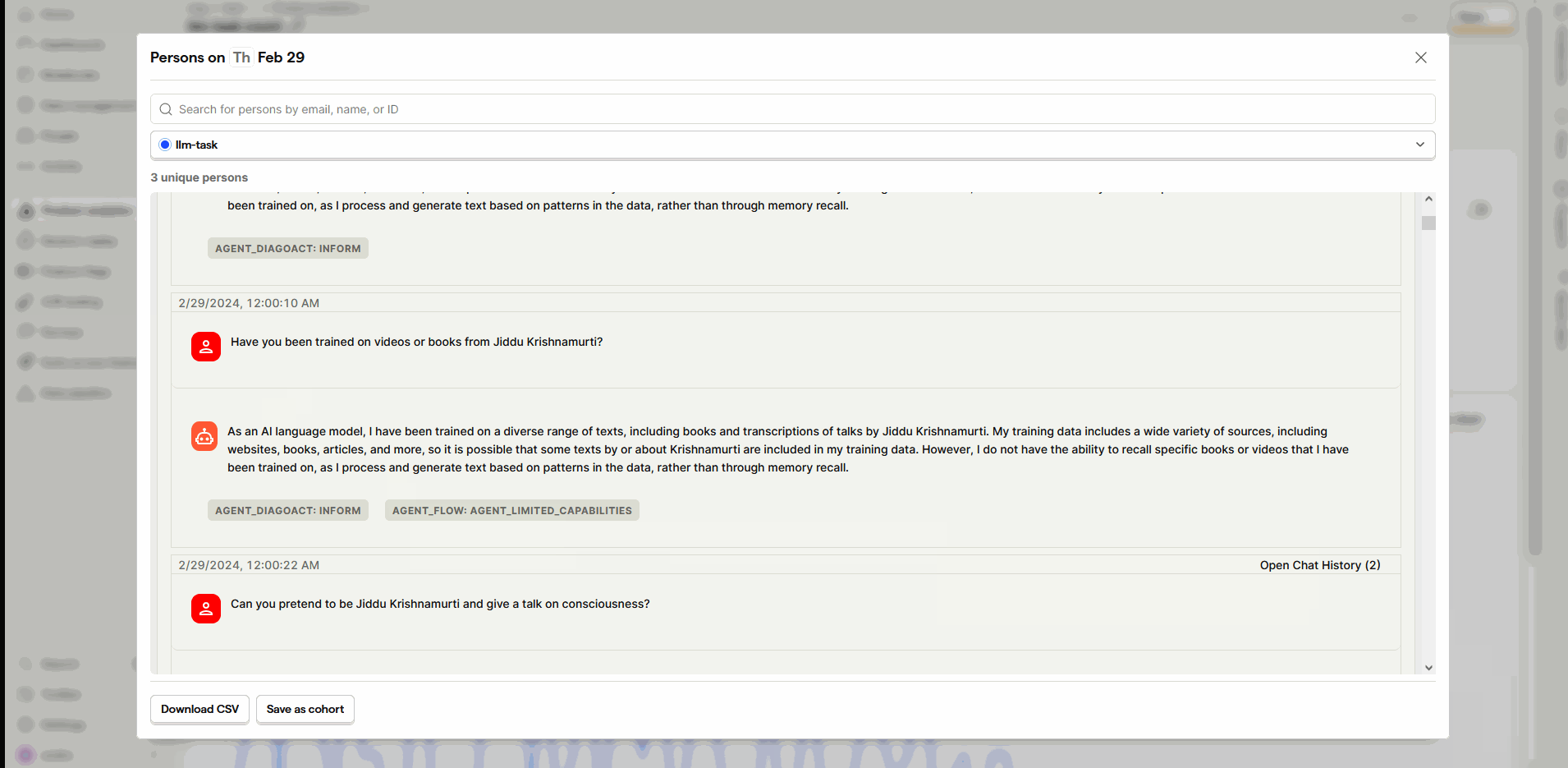
PostHog-LLM is a fork of PostHog with extensions
to use PostHog as a LLM text analytics platform and be able to display the LLM
interactions while exploring insights. Understand user behavior interacting with your LLMs to gain insights into their preferences, identify patterns and discover how you can improve your LLMs products to better serve your users.
Get started
Self-hosted
Deploy with CapRover
Faster and easier deployments. Check out caprover folder to deploy in minutes! ⚡
Hobby script
You can deploy a hobby instance in one line on Linux with Docker (recommended 4GB memory) (requires building the image):
To start uploading some user-LLM interactions to PostHog-LLM, checkout our demo-data folder or check out our repository with examples on how to upload data to PostHog-LLM.
Install Plugins
To maximize the capabilities of PostHog-LLM for analytics in LLMs, it’s important to augment LLM interactions with additional metadata. This enhancement can be done through the deployment of machine learning models as PostHog plugins. Examples of such plugins, which are available in their respective repositories, include:
LLM conversation flow classifier: Enhances understanding of the conversation with specific agent and user flow labels.
These plugins link the PostHog data ingestion process with the machine learning models. These models need to be hosted on separate servers, a setup process that is detailed within each model’s repository.
To install a plugin, navigate to the Data Pipeline section within the PostHog-LLM user interface, select the ‘Manage apps tab’ tab, click on Install app advanced button and enter the GitHub repository URL of the plugin into the designated field. This action will fetch the plugin’s code from GitHub and initiate its installation. Hit the Save button and then go to the Apps tab to specify the address and port of your model server in the API_SERVER_URL (e.g. http://localhost:9612) field.
PostHog’s plugin system is designed to facilitate the configuration of a model pipeline, enabling sequential data processing where each model can access and use properties appended by preceding models. The order of these models, as displayed in the PostHog UI, is important for ensuring that each model operates on the enriched dataset provided by its predecessors. PostHog-LLM adheres to a naming convention for LLM properties, and the machine learning models above are triggered exclusively for LLM events that include interaction texts.
PostHog is an all-in-one, open source platform for building better products
Specify events manually, or use autocapture to get started quickly
Analyze data with ready-made visualizations, or do it yourself with SQL
Gather insights by capturing session replays, console logs, and network monitoring
Improve your product with A/B testing that automatically analyzes performance
Safely roll out features to select users or cohorts with feature flags
Send out fully customizable surveys to specific cohorts of users
Connect to external services and manage data flows with PostHog CDP
SQL access: Use SQL to get a deeper understanding of your users, breakdown information and create completely tailored visualizations
Session replays:Watch videos of your users’ behavior, with fine-grained filters and privacy controls, as well as network monitoring and captured console logs
Heatmaps: See where users click and get a visual representation of their behaviour with the PostHog Toolbar
Feature flags: Test and manage the rollout of new features to specific users and groups, or deploy flags as kill-switches
A/B and multivariate experimentation: run simple or complex changes as experiments and get automatic significance calculations
Correlation analysis: Discover what events and properties correlate with success and failure
Surveys: Collect qualitative feedback from your users using fully customizable surveys
Data and infrastructure tools
Import and export your data: Import from and export to the services that matter to you with the PostHog CDP
Plays nicely with data warehouses: import events or user data from your warehouse by writing a simple transformation plugin, and export data with pre-built apps – such as BigQuery, Redshift, Snowflake, and S3
Our mission is to increase the number of successful products in the world. To do that, we build product and data tools that help you understand user behavior without losing control of your data.
In our view, third-party analytics tools do not work in a world of cookie deprecation, GDPR, HIPAA, CCPA, and many other four-letter acronyms. PostHog is the alternative to sending all of your customers’ personal information and usage data to third-parties.
PostHog gives you every tool you need to understand user behavior, develop and test improvements, and release changes to make your product more successful.
PostHog operates in public as much as possible. We detail how we work and our learning on building and running a fast-growing, product-focused startup in our handbook.
Open-source vs. paid
This repo is available under the MIT expat license, except for the ee directory (which has it’s license here) if applicable.
Need absolutely 💯% FOSS? Check out our posthog-foss repository, which is purged of all proprietary code and features.
Proposed new database schema for bbPress to imporve speed of database queries by no longer using wp_postmeta for additional forum, topic and reply data.
Why database need to be changed?
The new schema is proposed to use additional table as a replacement for the use of wp_postmeta for storing additional data used by forums, topics and replies. Database queries that need to join with the data in the wp_postmeta are very slow because join in the SQL is made on the meta_value column (type is LONGTEXT). This column can’t be indexed, and it requires casting to get proper data format, and that can make SQL queries execution very slow.
The speed of bbPress queries that depend on the wp_postmeta joining is not critical issue for small forums, but with larger number of topics and replies, it can considerably slowdown the website for more complex queries.
Without these changes, bbPress can’t scale well to large forums that run complex queries or have features that need better filtering, search and other things that use complex queries.
Which new tables are needed?
This proposition currently includes 3 tables for forums, topics and replies, 2 tables for topics and forums subscriptions, 1 table for favorite topics, 1 table for topics engangements and 1 table for users.
Tables for forums, topics and replies are made to replicate data saved into wp_postmeta table. Each column in these tables corresponds to the meta field stored in the wp_postmeta table. All ID based columns are indexed to make required joins very fast. Proper data types are used for all columns.
Users table replicates user data saved into wp_usermeta table. But, this table includes few more columns for some useful data related to users, and it can be expanded even more if needed.
How much faster queries can be?
From my own preliminary testing, complex queries can be 50 to 100 times faster. This doesn’t mean that bbPress will be 50 times faster, it all depends on the size of the forums, user activity, used features and other things.
My plugin GD bbPress Toolbox Pro uses custom database tables to track read status for topics and forums, and uses one extra table with indexed ID columns. First version of the code was made with the use of wp_postmeta. On a small forum (under 1000 forums, topics and replies combined), custom table based queries were only 2 times faster then the post meta based query. But, with larger forum with up to 100000 posts, custom table based queries were 30 times faster, and with a forum with 250000 posts, queries were almost 60 times faster.
Similar improvements are expected for bbPress core when transitioned to the custom database tables. This repository contains few examples of queries that show how faster the proper database schema is, using some practical queries.
How much work is needed to make changes to the bbPress?
There are few things that needs to be done:
Add install script to create database tables.
Create central database handling object for writing and reading from the extra tables.
Modify the forum maintenance code to recalculate all the data into new tables.
Create migration tool to guide user through the update process.
Replace all post meta handling functions (add, update, delete) with new code.
Modify all SQL queries to use new tables.
Modify all WP_Query based code to use new tables.
Update all the converters to use new database object.
What is next?
I would like to see suggestions on how to improve the database tables and make sure they are future proof and that bbPress can be updated and modified to use them.
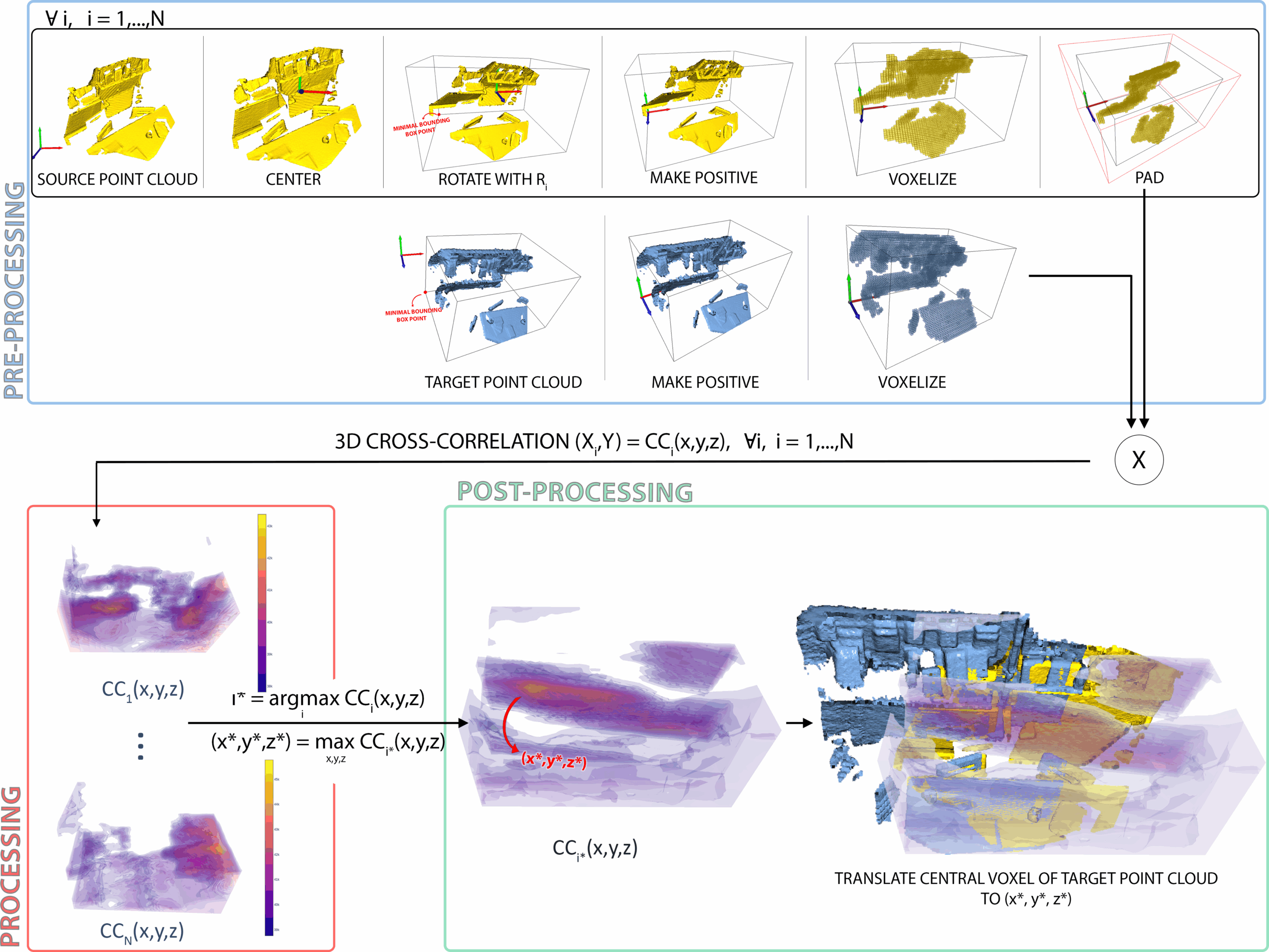
We analyze the problem of 3D registration and highlight 2 main issues:
Learning-based methods struggle to generalize onto unseen data
The current 3D registration benchmark datasets suffer from data variability
We address these problems by:
Creating a simple baseline model that outperforms most state-of-the-art learning-based methods
Creating a novel 3D registration benchmark FPv1 (called FAUST-partial in the paper) based on the FAUST dataset
Data
3DMatch
Download the testing examples from here under the title Geometric Registration Benchmark –> Downloads. There are 8 scenes that are used for testing. In total, there are 16 folders, two for each scene with names {folder_name} and {folder_name}-evaluation:
We use the overlaps from Perfect Match [2] (found in data/overlaps) to filter the data and use only those with overlap > 30%. We obtain the overlaps from their overlapMatrix.csv in each scene.
FPv1 (called FAUST-partial in the paper)
Download the FAUST scans from here. There are 100 scans in the training dataset named tr_scan_xxx.ply that are used for the registration benchmark. To use the same benchmark as in the paper, download the folder FPv1 from here.
We provide a Dockerfile to facilitate running the code. Run in terminal:
cd docker
sh docker_build.sh
sh docker_run.sh CODE_PATH DATA_PATH
by adjusting the CODE_PATH and DATA_PATH. These are paths to volumes that are attached to the container. The CODE_PATH is the path to the clone of this github repository, while the DATA_PATH is the location of all the data from data section in this documentation.
You can attach to the container using
docker exec -it ggs-container /bin/bash
Next, change the DATASET-PATH for each dataset in config.yaml.
Next, once inside the container, you can run:
pythonregister.py-Dxxx
where xxx can be 3DMatch, KITTI, ETH or FP (indicating FPv1). The script saves the registration results in results/timestamp, where timestamp changes according to the time of script execution.
Running refinement
To refine the results from the baseline registration, we provide a script that runs one of the three ICP algorithms:
p2point icp
p2plane icp
generalized icp
To choose between the three algorithms and set their parameters, adjust the REFINE option in config.yaml
pythonrefine.py-Rresults/timestamp
where timestamp should be changed to the baseline results path you want to refine.
Evaluate
Similarly to the refinement above, to evaluate the registration you can run:
pythonevaluate.py-Rresults/timestamp
where timestamp should be changed accordingly to indicate your results.
Running demo
We additionally provide a demo script demo.py for registering two arbitrary point clouds. First, adjust the parameters in config.yaml under the DEMO category. Next, you can run
where you need to specify the target and source point cloud paths.
Citation
If you use our work, please reference our paper:
@inproceedings{Bojanić-BMVC22-workshop,
title = {Challenging the Universal Representation of Deep Models for 3D Point Cloud Registration},
author = {Bojani\'{c}, David and Bartol, Kristijan and Forest, Josep and Gumhold, Stefan and Petkovi\'{c}, Tomislav and Pribani\'{c}, Tomislav},
booktitle={BMVC 2022 Workshop Universal Representations for Computer Vision},
year = {2022}
url={https://openreview.net/forum?id=tJ5jWBIAbT}
}
Now, install yarn globally (and optionally, check its version):
npm install -g yarn
yarn --version
Now you’re good to go! Build and serve the app using:
yarn build
yarn serve
Or, you can use the development server:
yarn start
Auto-generated Files
Please avoid modifying the following files by hand:
Anything in .yarn/
Anything in _generated/
.pnp.cjs
.pnp.loader.mjs
yarn.lock
These files are automatically managed by Yarn and Jest.
Not Yet Implemented
In trying to figure out the nicest and most well-supported ways of doing things, I’ve run into a couple features that I’m not sure how to include in this boilerplate. These are:
Moving all tooling configuration into internals.
Mobile icons.
I have no idea why internals/global.d.ts works even though I haven’t explicitly referenced it anywhere.
If I add "include": ["internals/global.d.ts"], to tsconfig.json, type checking no longer works. I have no idea why.
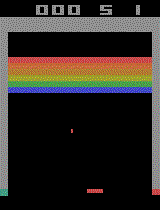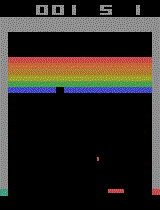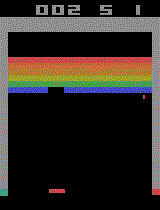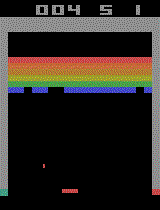
This project tackles the training of a DQN (Deep Q-Network) agent
to learn how to play the popular Atari game “Breakout”.
the training was done on a 8cpu GCP VM,
and it took a whole day to train the agent for 1M
iteration.
The agent reached a superhuman level
(meaning it never loose) by just trail
and error and using only the game image as an input
(Like any human player).
lot of this work is inspired by Auélien Géron’s Book
“Hands-On Machine learning with Scikit-Learn, Keras
& TensorFlow” https://github.com/ageron/handson-ml2/
Run project locally
create a conda environment using the requirement.txt file:
conda create –name rl_env –file requirement.txt
and you are all set !
This uses Tensorflow 2.0 and TF-agents 0.3.
Workes and tested on Window10 and Linux as well
Restaurant Recommendation Enginer – Content Based and Personalized (Yelp Dataset)
Description
Developed a content based recommender that recommends restaurants to the users.
Extracted, pre-processed, and cleaned the data related to restaurants from Yelp academic dataset.
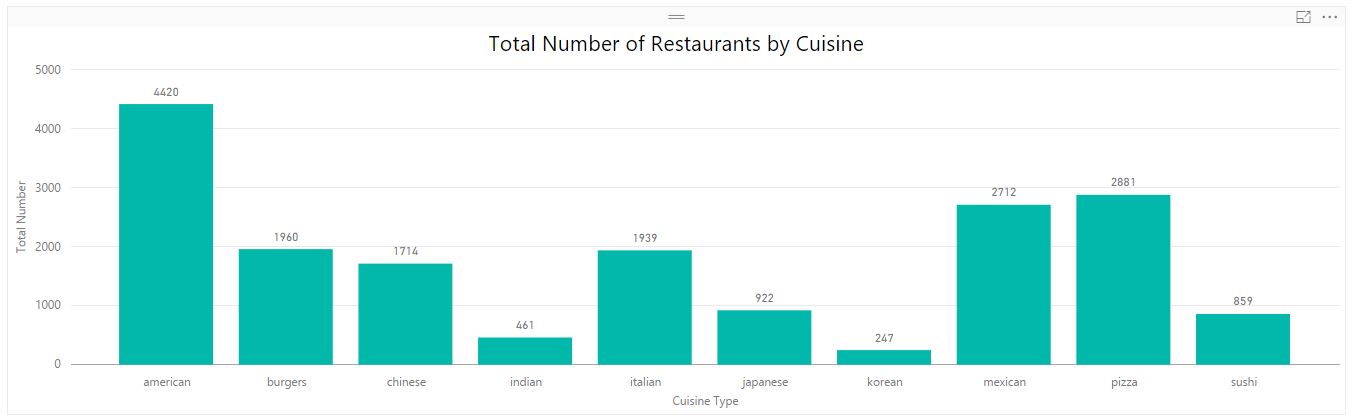
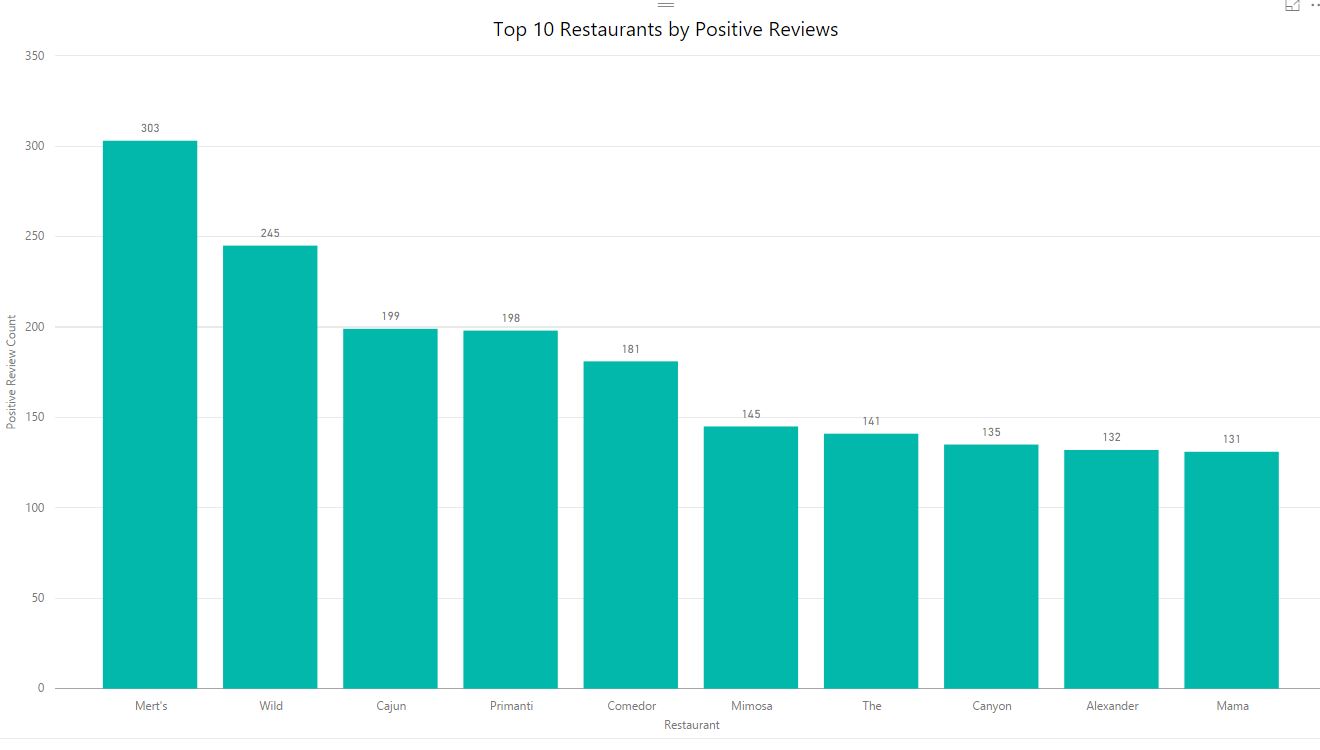
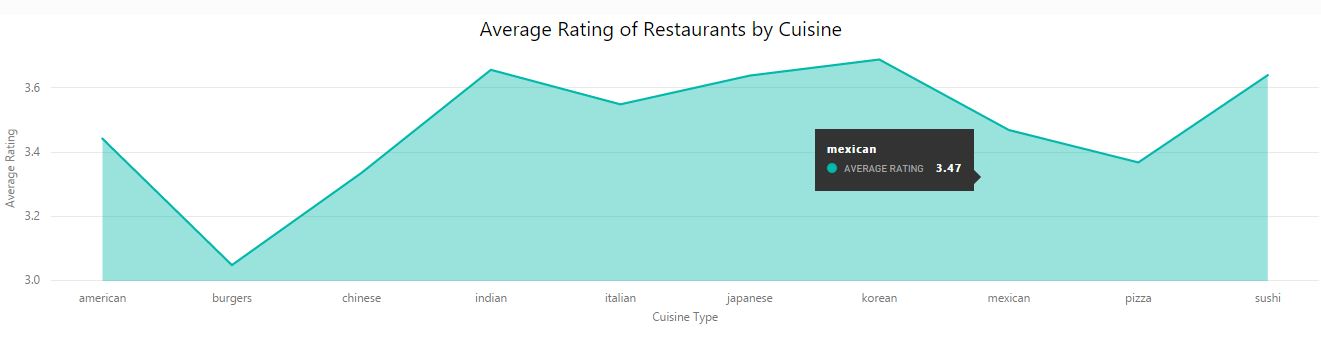
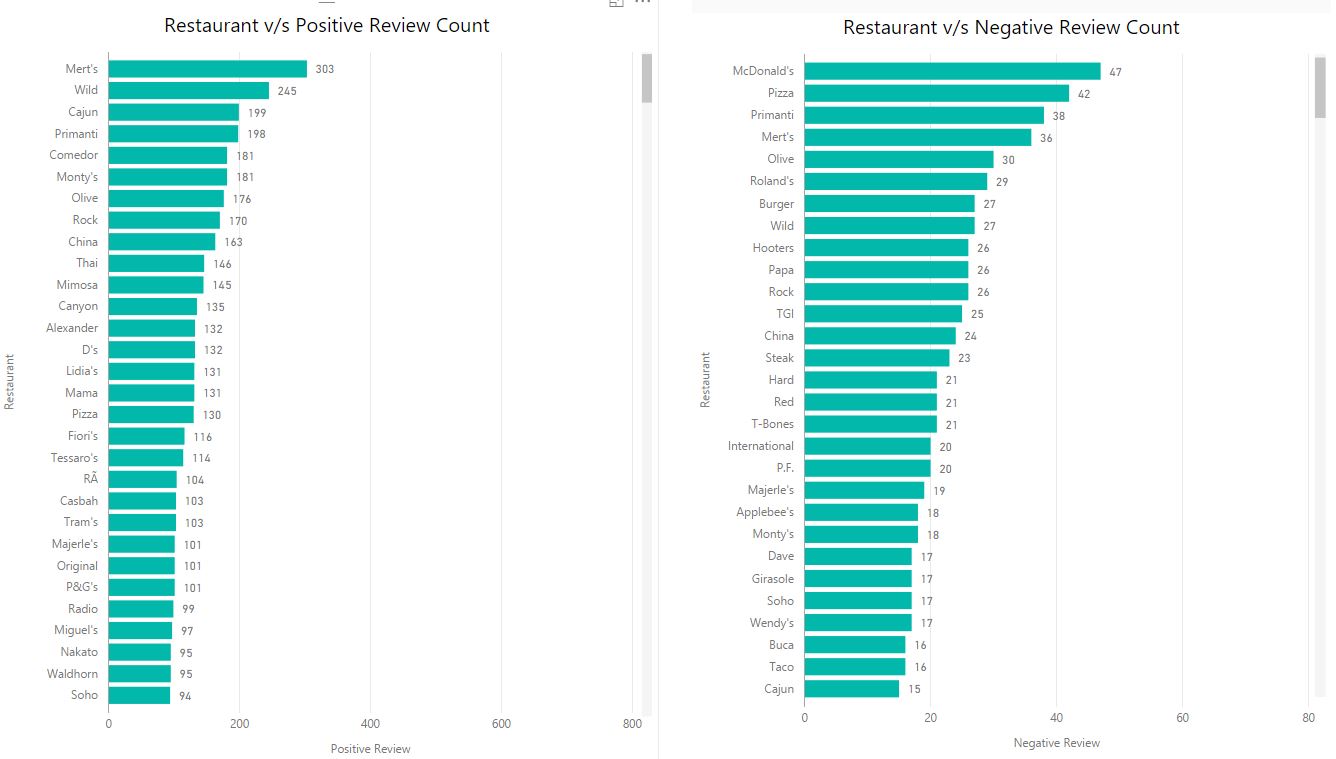
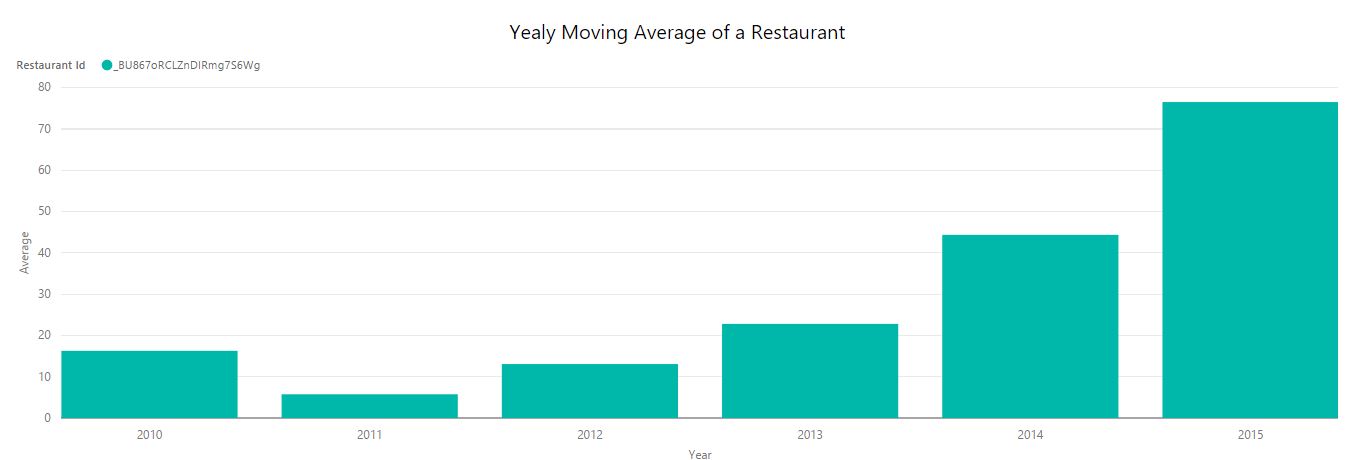
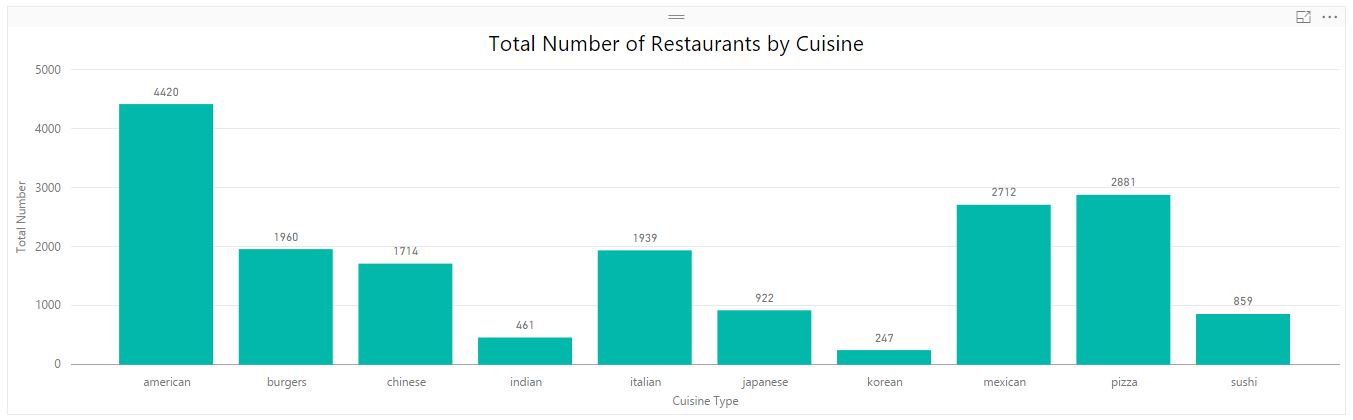
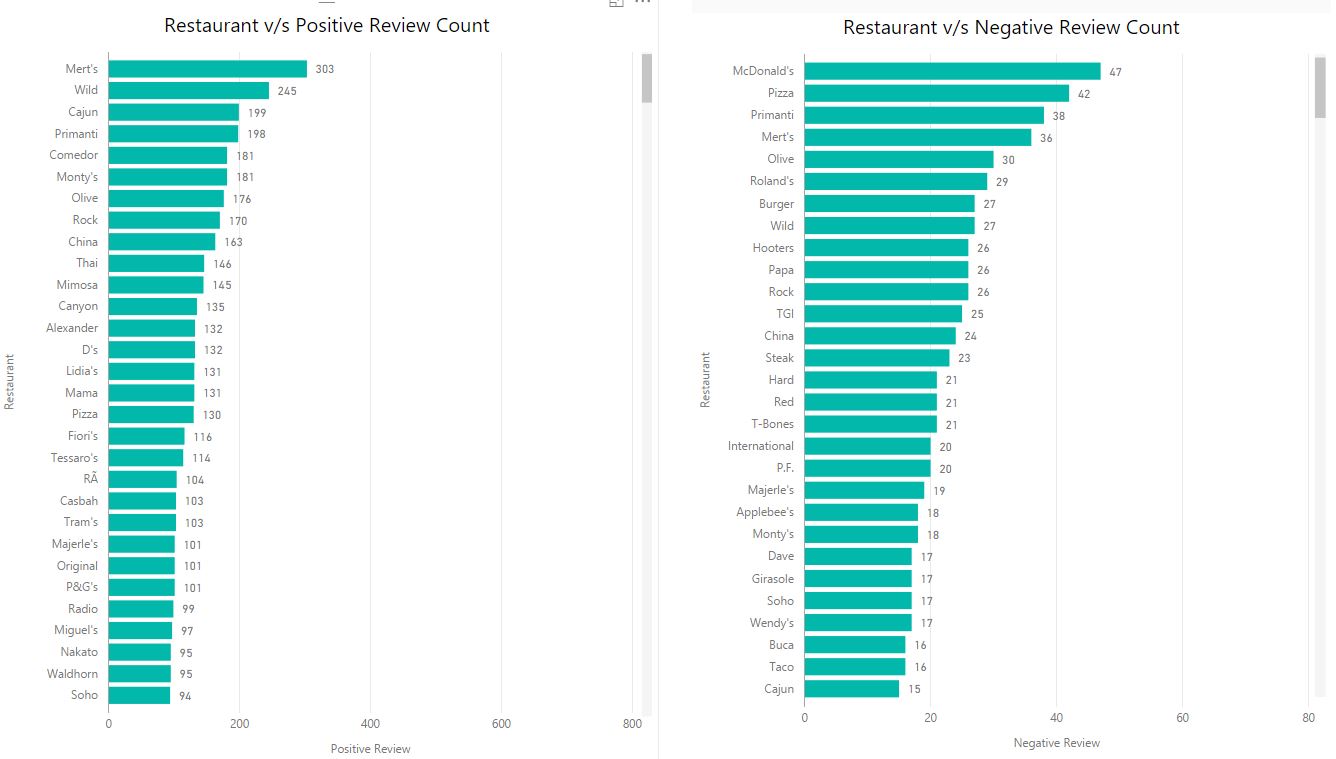
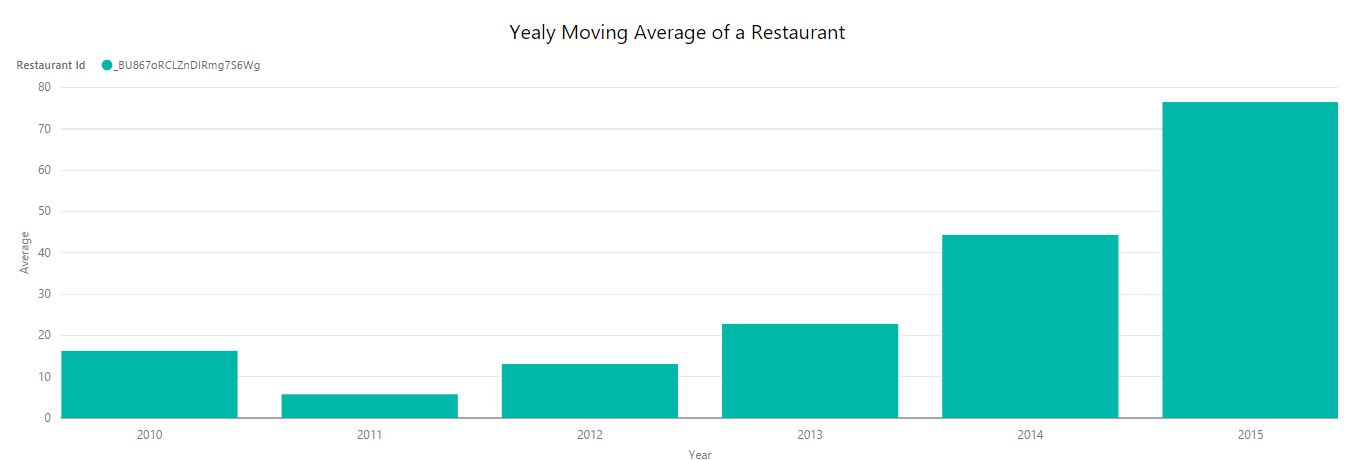
Implemented mapreduce design patterns like filtering, summarization, data organization, and join patterns to perform analysis such as top restaurants by country and state, total restaurants by country and state, moving average rating of restaurants, top restaurants by positive reviews, minimum and maximum review count of each restaurants, etc.
Performed sentiment analysis of the reviews about the restaurants given by Yelp users.
Calculated the pearson correlation, jaccard correlation and cosine correlation between restaurants to recommend to users.
Performed bining to split the data source on the basis of a preset value of a column and bloom filtering to filter the restaurants on basis of cities they are located in.
Deployed the project on AWS EC2 with 4 instances comprising of a namenode, a secondary namenode and two data nodes to achieve high scalability and performance.





 https://github.com/DEENUU1/DJANGO-WEATHER-MUSIC
https://github.com/DEENUU1/DJANGO-WEATHER-MUSIC