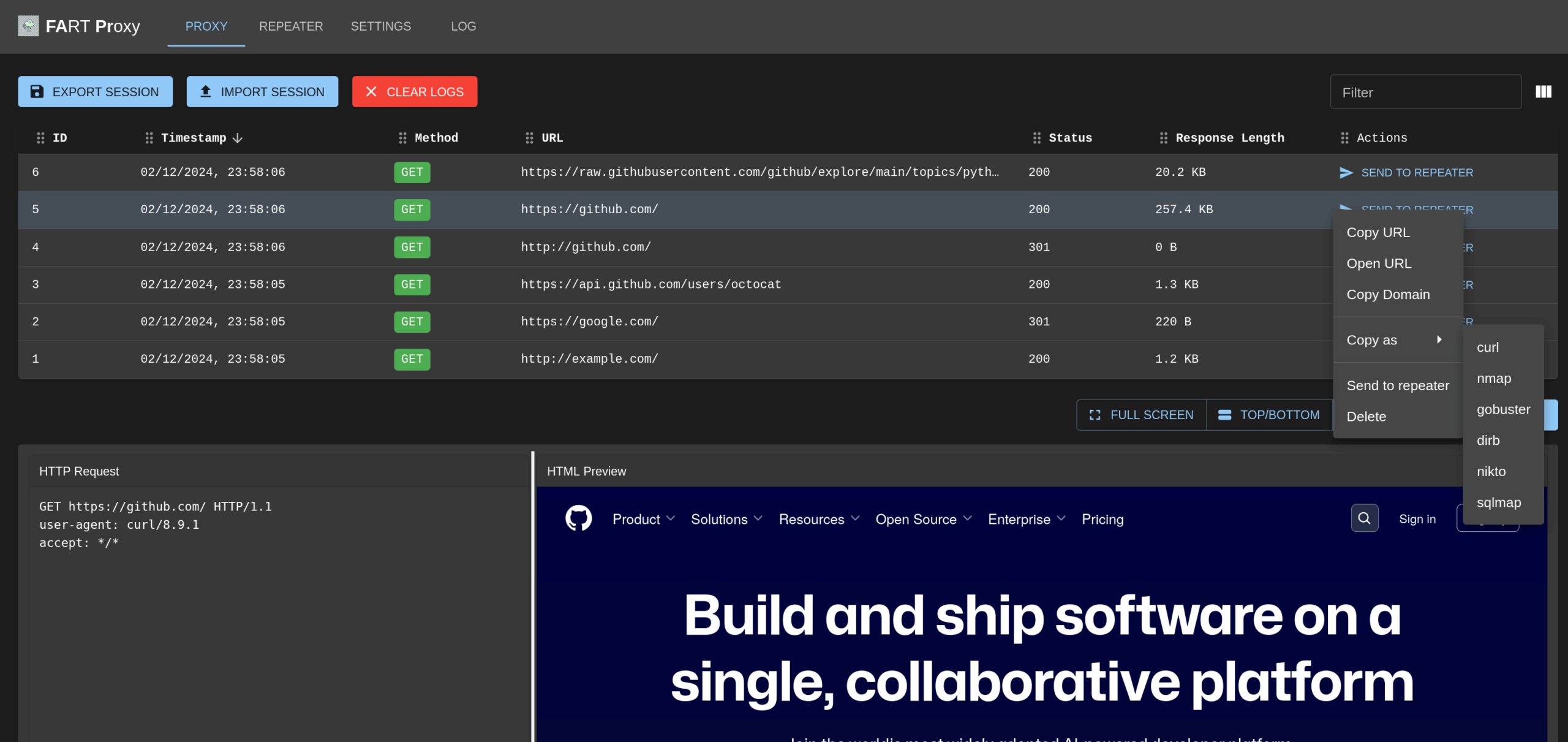


FART is a Man-in-the-Middle (MITM) proxy tool built with mitmproxy as the backend and React.js for the frontend web UI. It provides a user-friendly interface for intercepting, analyzing, and modifying HTTP/HTTPS traffic.
-
Multi-tab Interface:
- Proxy Tab: View and filter intercepted traffic, export/import sessions
- Repeater Tab: Modify and replay captured requests
- Settings Tab: Configure proxy settings and filtering rules
-
Session Management:
- Export sessions to JSON files
- Import previously saved sessions
- Base64 encoding for preserving binary data
-
Request Manipulation:
- Send intercepted requests to Repeater
- Modify and replay requests
- View detailed request/response information
-
Start the application (choose one method):
# Using Docker script (recommended) ./run-docker.sh # Or manually with Docker mkdir -p sessions # Create directory for persistent proxy history docker run --rm --init --sig-proxy=false -p 3001:3001 -p 8001:8001 -p 8080:8080 \ -v $(pwd)/sessions:/app/backend/src/api/sessions \ fart-proxy # Or using run script for local development ./run.sh
-
Install mitmproxy certificate:
# Download and install the certificate mitmdump --set ssl_insecure=trueThen press ‘q’ to quit mitmdump. The certificate will be installed at:
- Linux:
~/.mitmproxy/mitmproxy-ca-cert.pem - macOS:
~/Library/Application Support/mitmproxy/mitmproxy-ca-cert.pem - Windows:
%USERPROFILE%\.mitmproxy\mitmproxy-ca-cert.p12
- Linux:
-
Configure your system/browser to use the proxy:
- Proxy Host: localhost
- Proxy Port: 8080
-
Test the proxy:
# Test HTTP traffic curl -x localhost:8080 http://example.com # Test HTTPS traffic (use -k to allow self-signed certificates) curl -x localhost:8080 -k https://example.com
-
Access the web interface at
http://localhost:3001
-
Build the image:
docker build -t fart-proxy . -
Run the container:
# Create directory for persistent proxy history mkdir -p sessions # Basic run with volume mount for persistent history docker run --rm --init --sig-proxy=false -p 3001:3001 -p 8001:8001 -p 8080:8080 \ -v $(pwd)/sessions:/app/backend/src/api/sessions \ fart-proxy # Or with explicit API host configuration (if needed) docker run --rm --init --sig-proxy=false -p 3001:3001 -p 8001:8001 -p 8080:8080 \ -v $(pwd)/sessions:/app/backend/src/api/sessions \ -e REACT_APP_API_HOST=localhost \ -e REACT_APP_API_PORT=8001 \ fart-proxy
Note:
- The volume mount (-v flag) ensures your proxy history persists between container restarts
- The environment variables are optional and only needed if you’re running behind a reverse proxy or need to specify a different API host
- The –init flag ensures proper signal handling
- The –sig-proxy=false flag prevents signal proxying for clean container shutdown
- The –rm flag automatically removes the container when it stops
- Python 3.8+
- Node.js 14+
- npm or yarn
-
Clone the repository:
git clone <repository-url> cd fart
-
Set up the backend:
cd backend python -m venv venv source venv/bin/activate pip install -r requirements.txt
-
Set up the frontend:
cd ../frontend npm install
# Copy the certificate
sudo cp ~/.mitmproxy/mitmproxy-ca-cert.pem /usr/local/share/ca-certificates/mitmproxy.crt
# Update certificates
sudo update-ca-certificates# Convert PEM to CER
openssl x509 -outform der -in ~/Library/Application\ Support/mitmproxy/mitmproxy-ca-cert.pem -out mitmproxy-ca-cert.cer
# Double click the certificate in Finder and add to System keychain- Double click the
.p12file in%USERPROFILE%\.mitmproxy\ - Install for “Local Machine”
- Place in “Trusted Root Certification Authorities”
- All HTTP/HTTPS traffic passing through the proxy will be displayed in the table
- Use the filter box to search through captured requests
- Click “Send to Repeater” to analyze and modify specific requests
- Use Export/Import buttons to save and load sessions
- Modify any part of the request (method, URL, headers, body)
- Click “Send Request” to replay the modified request
- View the server’s response in real-time
- Use “Clear” to reset the request/response fields
- Configure proxy port and UI port settings
- Set debug level for logging
- Enable/disable request filtering
- Add filtering rules to control which requests are captured
- Verify certificate installation:
# Test HTTPS connection curl -x localhost:8080 -k https://example.com - Check certificate location:
- Linux:
~/.mitmproxy/mitmproxy-ca-cert.pem - macOS:
~/Library/Application Support/mitmproxy/mitmproxy-ca-cert.pem - Windows:
%USERPROFILE%\.mitmproxy\mitmproxy-ca-cert.p12
- Linux:
- Verify proxy is running:
curl -v -x localhost:8080 http://example.com
- Check port availability:
# Check if ports are in use lsof -i :8080 lsof -i :8001 lsof -i :3001
- Check container logs:
docker logs <container-id>
- Verify port mappings:
docker ps
- Check proxy history persistence:
# Verify the sessions directory exists and has proper permissions ls -la sessions/ # Check if history.json exists and is writable ls -la sessions/history.json
- If proxy history isn’t showing:
- Ensure the sessions volume is mounted correctly
- Check the browser console for any API connection errors
- Verify the container can write to the sessions directory
- Backend API: FastAPI with mitmproxy integration
- Frontend: React with Material-UI components
- State Management: React hooks and context
- API Communication: Axios for HTTP requests
- Fork the repository
- Create a feature branch
- Commit your changes
- Push to the branch
- Create a Pull Request
MIT License – feel free to use and modify for your needs.
 https://github.com/rascal999/fart
https://github.com/rascal999/fart